Creating a transcription file
There are several ways to create a transcription file, but for Windows users our bespoke program WinREG is the best choice. For those on Mac or Linux, we recommend using a spreadsheet, as found in any office software.
A FreeREG file should be no larger than about 2,000 records. We strongly recommend that those records be all for the same Place, Church and Register type: that is, they should amount to a single Batch.
Before you begin to work, you must ensure that you have the necessary Permission to transcribe? for your source.
WinREG
Use this link to download the WinREG installer as a zip file (the most recent version of WinREG 3), then unzip it and run the installer. WinREG is written by Mike Fry, an experienced transcriber.
WinREG on Windows 10
We are aware that some users of WinREG are experiencing problems after a Windows 10 update. Please run your anti-virus check after the update: that should fix the issue, with no loss of data.
You may find that WinREG does not scale properly on Windows 10, making the text too small to read. Here is the fix:
Find the WinREG.exe file using Windows Explorer: navigate to your C drive — Program files (x86) — FreeREG — WinREG for Windows. Now right-click on WinREG.exe and select Properties, then Compatibility, then Settings.
Now select Change high DPI settings, then click the bottom option, Override/disable high DPI settings, to tick its box. Click on OK, then the next OK, to confirm and finish.
There are many advantages to using WinREG:
- Your files will be ‘database ready’ without any of the extra work required by using other programs.
- You will be asked for your details only once: these will be put automatically into every file you create.
- It is also easy to edit the other details that vary from file to file. (These correspond to the remaining file Header fields, if you have previously used a spreadsheet.)
- The field names (column names in a spreadsheet) will be created for you, according to whether you are transcribing baptisms, marriages or burials.
- You can rearrange the fields so that they are in an order that follows the order of information in your source. When you save a file, WinREG will save the fields in the order that the database expects.
- You can also hide any fields that your source does not have data for, just as you can with a spreadsheet.
Spreadsheet
If you are not able to use WinREG for any reason, then we recommend using a spreadsheet, especially one from the Open Source office suites: the first two are available for Windows, Mac OS X and Linux; they are also free of charge.
- Apache OpenOffice
- LibreOffice
- NeoOffice is for Mac OS X only and there is a small charge (starting at £8 or $10 at time of writing)
A modern version of Microsoft Excel can be used, but we do not recommend older versions as they have a bug in the way they save CSV files — the kind of file that must be uploaded to the database. There is a way around this bug, but the fix involves extra work, and may itself introduce a different problem.
Other proprietary spreadsheets are available, but we have less collective experience with these.
You don't need to know how to do anything complicated with the spreadsheet, just how to: Save, Save as, and set the format of cells in a column (field) to Text. It would also be very useful to know how to freeze the headings, so that they are always visible. In addition, we ask that you turn off all the AutoCorrect options — the details of why and how are in the box below.
We strongly recommend that you save your working file in the spreadsheet's own format (file ending). This will make it simpler to re-open the file and will preserve such things as column widths and font size for when you next work on your transcription. We also strongly recommend that you set the cell format for the whole sheet to text — this will avoid issues with the header cells that contain a + (plus) sign and also with dates.
AutoCorrect
AutoCorrect or Substitution is now a common feature in many applications: even the so-called plain text editors like Notepad or TextEdit are not so plain any more. The default (or out of the box) setting is to have the feature turned on: this is not a problem for many kinds of writing, but for a database project like FreeREG, there are lurking dangers.
Many of the corrections applied by AutoCorrect are to do with the casing of letters and the common typing errors people make with words. AutoCorrect can ensure that all sentences start with a capital (upper case) letter; it can prevent you beginning a word with two capital letters; and it can change the word i to I. It can also correct typos like abotu to about, or acn to can. This is not a problem in itself, but for FreeREG work, you will want to be in full control of how words are spelt and cased. The main problem is that AutoCorrect changes some plain punctuation to their smart (fancy or typographers) versions.
A good example of AutoCorrect in action with punctuation happens like this: you type a plain double quotation mark on your keyboard: it starts out looking like ", but as soon as you type the next thing, it changes magically to “ — the plain quote has been converted to a fancy or smart quote. Again, this is not a problem for most kinds of writing (indeed, it is useful for a party invitations or a novel), but for FreeREG it is a problem.
As well as changing " to “ or ”, other common substitutions are the single quotation mark (and apostrophe), ' to ‘ or ’; ellipses, ... (three characters) to … (one character); and dashes, (space hyphen space or two hyphens to — (an em-dash).
The exact form of the smart punctuation will vary from font to font, but there is less difference when comparing the plain forms. For the quotation marks, the plain forms will be vertical, with left and right quotes looking the same. (If you are having trouble seeing the difference, try zooming in: see your browser's View menu.)
The problems
Searching
If smart punctuation is used instead of plain, then a search for a surname like O'Grady will not find all the possible matches: the O'Grady entries will be found, but not O’Grady. The visual difference between the two apostrophes is small, but the effect on a search could be huge.
Similarly, most abbreviations of a forename will be found automatically in a search, but any that include a smart apostrophe will not be found. So Tho's will be found in a search for Thomas, for example, but not Tho’s.
Garbled entries
If your file has been saved using one character set, but the character set in the Headers is not the same, then any smart punctuation will not be understood by the database and you will see groups of characters like these in your uploaded batch: … “ � ‘ ’.
This is most likely to happen when files are passed on to someone else for editing or Uploading: the remedy is to turn off all the AutoCorrect options, then re-type the problem punctuation. Finally, make sure that you put the correct character set in cell 1F of the Headers (see the File Headers page for details).
How to turn AutoCorrect off
Start with a blank spreadsheet open: this will prevent you seeing any options that do not apply to spreadsheets. From the menu, select Tools > AutoCorrect Options. You will get a dialog box with four parts: Replace, Exceptions, Options, Custom Quotes or Localised Options. (Note that OpenOffice, for example, has a fifth part, Word Completion, which you will see if you do not have a blank spreadsheet open: you can ignore it.)
The third and fourth parts are the important ones: the first and second contain the details of how some correction options are applied — we are going to turn those options off.
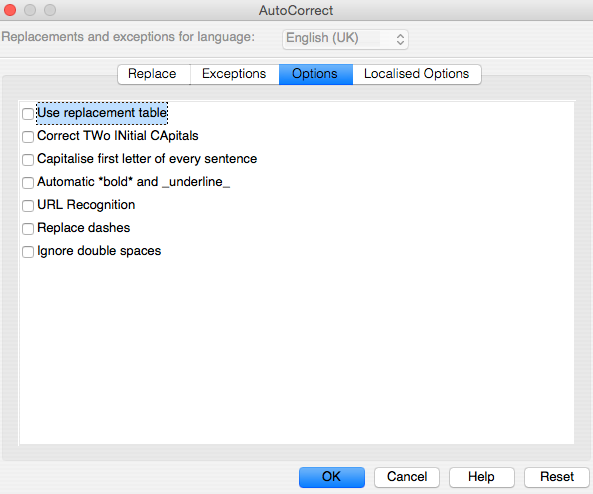
Part three (Options) has a list of possible corrections: simply de-select all of these.
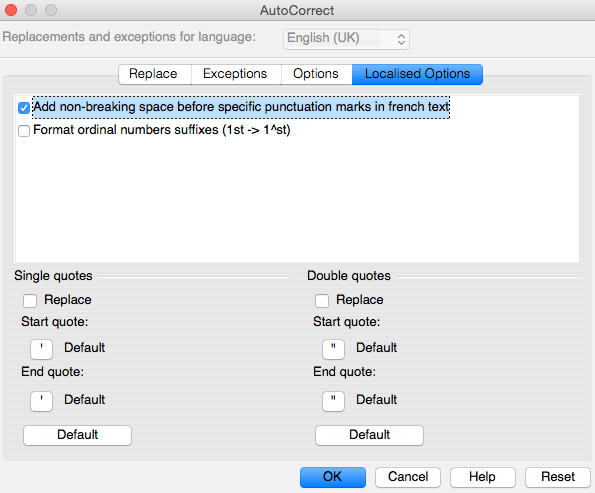
Part four (Custom Quotes or Localised Options) deals with quotation marks: un-check both Replace boxes. Un-check anything else that is offered here for writing in English.
Naming your file
The CSV file, described below, that you will Upload or Replace on the server needs to be named according to the following pattern. The first 8 letters of the name are:
- the 3-letter County code (as listed on the Chapman codes page)
- the 3-letter Place code (please ask your Coordinator for this code)
- a 2-letter code that describes the event type: BA (baptisms), BU (burials) or MA (marriages)
For smaller registers of around two thousand records or fewer in total, these eight letters are all you need. However, if you are going to be transcribing a larger register of more than two thousand records, then you will need to append a number to each filename to distinguish each part of the transcription.
For example, a baptism register of about six thousand records for a (fictitious) Place with code ABC in the West Riding of Yorkshire will need three files: WRYABCBA1, WRYABCBA2, and WRYABCBA3.
If the register is large enough to need more than nine files to complete, then consider using two digits to number your files: this will result in a set of batches that sorts in a more natural order in batch listings. This is because batches are sorted in so-called dictionary order, so that WRYABCBA2, for instance, would be listed after WRYABCBA12, whereas WRYABCBA02 (which is numbered zero two) would be listed before it.
Add the headers
There is one more step which should be done in your spreadsheet application: adding the information that lets the database understand your transcription and know who created it. The instructions are on the File headers page. If you have any problems with this step, your Syndicate Coordinator will be pleased to help you.
Save as … CSV
When you have finished entering data, the next step is to save your file in CSV (or Comma-separated values) format. Just before doing so, delete the row of column labels, if you have not already deleted them as part of adding the file Headers.
With your spreadsheet open, use File, Save As to bring up a dialogue box. Choose Comma-separated values as the format, probably from a drop-down list. You may be asked to confirm (or choose) commas as the ‘field separators’ (or ‘field delimiters’), and double-quotes as the ‘text delimiters’: agree to both. It is not necessary to agree to all fields being quoted, but it will do no harm.
Please be aware that both the file name and the file extension are case-sensitive which means that, for example, the files SSXFERBA.CSV and SSXFERBA.csv are treated as two, separate, different files. To avoid any confusion in the future, please use exactly the same file extension for your files, either .CSV or .csv, but not a mixture of both.
A CSV file just a simple text file, with a .csv or .CSV extension (ending). Each data field (cell) is separated from the next by a comma, and each record is on its own line. For a baptism register, opened in a text editor such as Notepad or TextEdit (not a word processor), the beginning of the first two lines after the Headers might look something like this:
GLS,Ruardean,All Saints PR,,,06 Jun 1786,Elizabeth,F, …
GLS,Ruardean,All Saints PR,,,20 Jun 1786,James,M, …
Notice that some of the fields are empty in this example, with literally nothing between the commas: there are no unnecessary spaces.
First time check
This test is not necessary for users of Apache OpenOffice, LibreOffice or NeoOffice — all three pass.
If this is your first transcription file with Microsoft Excel (pre-2011) or another program not listed above, then this simple check will tell you whether or not it is suitable for FreeREG: in particular, some of the older versions of Excel have a bug in the way they save CSV files that makes them unsuitable.
The check is simply this:
- open the CSV file in a text editor (Notepad or TextEdit)
- find the end of a line that you know does not have data in the final field (column):
- if it ends with one or more commas, all is well!
- if there are no commas at the end, then you will need to use one of the free Office programs
Not sure? Some examples may help. A baptism entry with data in the final field — in this case, the Notes field — will end something like this, with no final comma:
… ,WARD,FORBES,"23, High St",,Mr Saml Ward
(Note also that one of the fields has double quotes around the contents: this is because the contents — 23, High St — has a comma in it. Fields without a comma are not quoted.)
Lines without data in the final field, should end something like these:
… ,BAIRD,,,,
… ,REYNOLDES,JONES,,Blacksmith,
A line without content in the final field should end with at least one comma. If you see one or more commas at the end of such lines, then your spreadsheet has been saved correctly. You will not need to do this check again.
However, if you’re seeing entries like these, with empty final fields but no final comma(s),
… ,BAIRD
… ,REYNOLDES,JONES,,Blacksmith
then you will need to download one of the free Office suites for your FreeREG transcriptions. (Experienced volunteers who use old versions of Microsoft Excel and the "dummy column" method without any problems may continue to do so, but we urge you to consider using a different spreadsheet, if possible.)
Database
If you are more comfortable with database software, then any that can save files in the required "Comma-separated values" (CSV) format will be suitable. You will need to add the headers to your completed CSV file, as described for spreadsheets. If your software has AutoCorrect or Substitution options, you need to turn off all that apply to punctuation.
Text editor
This method for FreeREG transcription is really only for people who use a text editor for everything and would not dream of using anything else. You would have to set everything up yourself, be good at counting commas and remember to quote fields that themselves contain commas. (Full details can be found on Entering data from registers.)
You would also have to enter the file Headers yourself, as described on File headers.
Plain text editors are no longer quite so plain. In particular, they may have an AutoCorrect or Substitution feature: you need to turn off all substitutions that apply to punctuation, especially for quotation marks, ellipses and hyphens/dashes. This applies even if you are just using a text editor to make a small edit of your file or someone else's file.
Please check that you know which character set your editor uses on saving: if offered a choice, then select utf-8 and put UTF-8 in line 1, field 6 (character set) of the file Headers.